
Lessons from building Claude Code: Prompt caching is everything
We share best practices for optimizing prompt caching in Claude Code, including how to most effectively structure your prompt, use tools, and layer on compaction.
We share best practices for optimizing prompt caching in Claude Code, including how to most effectively structure your prompt, use tools, and layer on compaction.
It is often said in engineering that "cache rules everything around me", and the same rule holds for agents.
Long running agentic products like Claude Code are made feasible by prompt caching which allows us to reuse computation from previous roundtrips and significantly decrease latency and cost.
At Claude Code, we build our entire harness around prompt caching. A high prompt cache hit rate decreases costs and helps us create more generous rate limits for our subscription plans, so we run alerts on our prompt cache hit rate and declare SEVs if they're too low.
These are the (often unintuitive) lessons we've learned from optimizing prompt caching at scale.

Prompt caching works by prefix matching—the API caches everything from the start of the request up to each cache_control breakpoint. This means the order you put things in matters enormously, you want as many of your requests to share a prefix as possible.
The best way to do this is static content first, dynamic content last. For Claude Code this looks like:
This way we maximize how many sessions share cache hits.
But this approach can be surprisingly fragile. We’ve broken this ordering before for a variety of reasons, including: putting an in-depth timestamp in the static system prompt, shuffling tool order definitions non-deterministically, and updating parameters of tools (e.g., what agents the Agent tool can call).
There may be times when the information you put in your prompt becomes out of date, for example if you have the time or if the user changes a file. It may be tempting to update the prompt, but that would result in a cache miss and could end up being quite expensive for the user.
Consider if you can pass in this information via messages in the agent’s next turn instead. In Claude Code, we add a <system-reminder> tag in the next user message or tool result with the updated information for the model, which helps preserve the cache.
Prompt caches are unique to models and this can make the math of prompt caching quite unintuitive.
For example, if you're 100k tokens into a conversation with Opus and want to ask a question that is fairly easy to answer, it would actually be more expensive to switch to Haiku than to have Opus answer, because we would need to rebuild the prompt cache for Haiku.
If you need to switch models, the best way to do it is with subagents; extending the above example, you could deploy a subagent that prompts Opus to prepare a "hand-off" message to another model on the task that it needs to get done. We do this often with the Claude Code’s Explore agents, which use Haiku.
Changing the tool set in the middle of a conversation is one of the most common ways people break prompt caching. It seems intuitive—you should only give the model tools you think it needs right now. But because tools are part of the cached prefix, adding or removing a tool invalidates the cache for the entire conversation.
Using Plan Mode to design around the cache
Plan Mode is a great example of designing features around caching constraints. The intuitive approach would be: when the user enters plan mode, swap out the tool set to only include read-only tools, but that would break the cache.
Instead, we keep all tools in the request at all times and use EnterPlanMode and ExitPlanMode as tools themselves. When the user toggles Plan Mode on, the agent gets a system message explaining that it's in Plan Mode and what the instructions are: explore the codebase, don't edit files, and call ExitPlanMode when the plan is complete. The tool definitions never change.
This has a bonus benefit: because EnterPlanMode is a tool the model can call itself, it can autonomously enter plan mode when it detects a hard problem, without any cache break.
Use tool search to defer instead of remove
The same principle applies to our tool search tool. Claude Code can have dozens of MCP tools loaded, and including all of them in every request would be expensive, but removing them mid-conversation would break the cache.
Our solution: defer_loading. Instead of removing tools, we send lightweight stubs ( just the tool name, with defer_loading: true) that the model can "discover" via tool search when needed. The full tool schemas are only loaded when the model selects them. This keeps the cached prefix stable because the same stubs are always present in the same order.
You can also use the tool search tool through our API to simplify this.
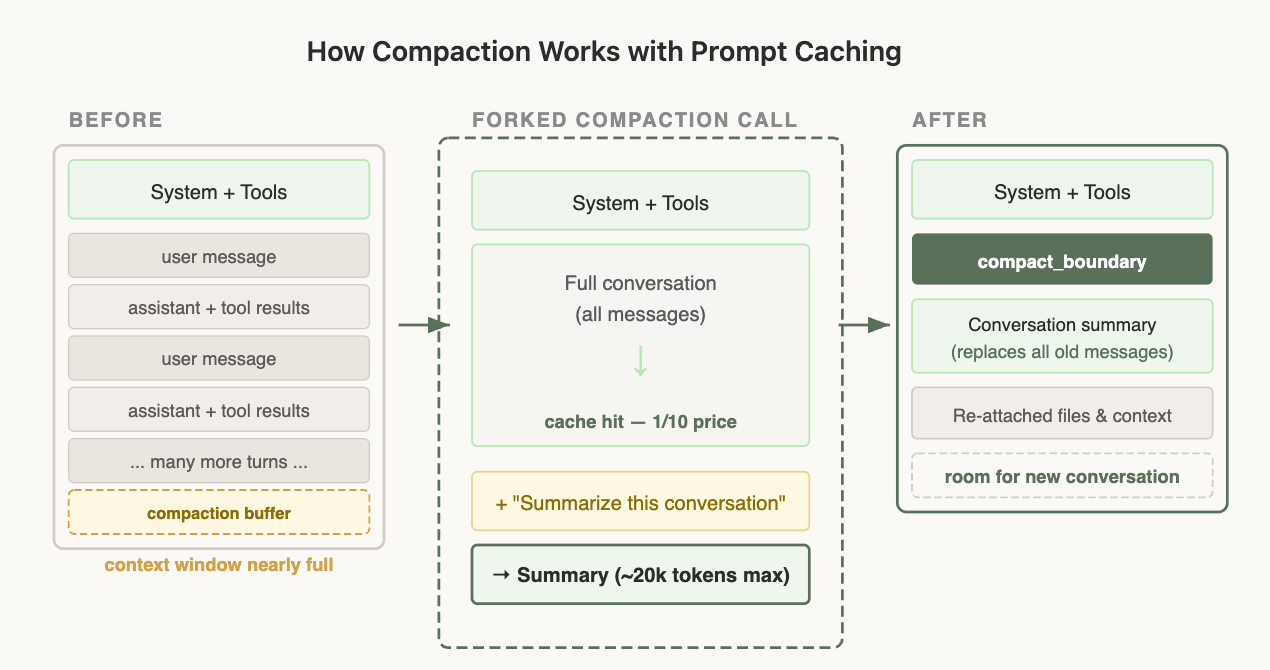
Compaction is what happens when you run out of the context window. We summarize the conversation so far and continue a new session with that summary.
Compaction interacts with prompt caching in ways that are easy to get wrong. To compact a conversation, you have to send the full conversation to the model so it can write a summary. The simplest way to do that is a separate API call with its own system prompt (something like "summarize this") and no tools attached, but that's exactly where the cost trap is. Prompt caching only applies when a request's prefix matches what's already cached, byte for byte, from the start. Your main conversation is cached under one system prompt and tool set; the summarization call uses a different system prompt and no tools, so the prefixes diverge at the very first token and none of the cache applies. You end up paying the full, uncached input rate for the entire conversation you're sending in — and the longer the conversation (i.e., the more you need compaction in the first place), the more expensive that one call becomes.
The solution: cache-safe forking
When we run compaction, we use the exact same system prompt, user context, system context, and tool definitions as the parent conversation. We prepend the parent's conversation messages, then append the compaction prompt as a new user message at the end.
From the API's perspective, this request looks nearly identical to the parent's last request—same prefix, same tools, same history—so the cached prefix is reused. The only new tokens are the compaction prompt itself.
This does mean however that we need to save a "compaction buffer" so that we have enough room in the context window to include the compact message and the summary output tokens.
Compaction is tricky but luckily, you don't need to learn these lessons yourself—based on our learnings from Claude Code we built compaction directly into the API, so you can apply these patterns in your own applications.
Here are a few patterns we’ve found useful for optimizing prompt caching when building an agent:
Claude Code is built around prompt caching from day one; for the best results when building an agent, we suggest you do, too.
Get started with Claude Code today.
This article was written by Thariq Shihipar, a member of technical staff on the Claude Code team.

Get the developer newsletter
Product updates, how-tos, community spotlights, and more. Delivered monthly to your inbox.



